Deploying Language Models With Gradio On Hugging Face
Machine learning models (including language models) can be easily deployed using generous free tier on Hugging Face and a python-based open source UI tool Gradio by following these steps.
See live deployed app and source code here
-
For local development, create the following Dockerfile. It differs from production Dockerfile in how secrets are loaded and the use of
CMD ["gradio", "app.py"]
which runs (and reloads) source files every time a change is noticed. -
docker-compose will launch the development Dockerfile using command
export HF_TOKEN=paste_HF_token && docker-compose -f docker-compose.yml up gradiohf
where HF_TOKEN is an optional personal token provided by Hugging Face to ensure that license restrictions are being followed for certain models (such as Llama 2). -
Develop your Gradio app.py. This deployed example represents the absolute smallest version that selects a language model based on environmenal variable os.environ.get("MODEL"). The selections includes Llama 2 which will require a paid Spaces plan to run on Hugging Face (with no code changes!). The live example runs a small toy model google/flan-t5-small that easily runs on the free tier.
-
View your Gradio app running locally in browser:
http://0.0.0.0:7860
-
Create production Dockerfile and deploy on Hugging Face Spaces using this great documentation.
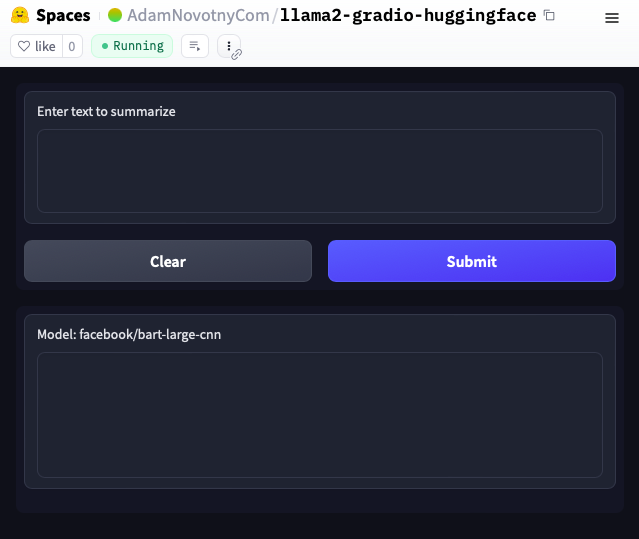
Example of Gradio UI deployed on Hugging Face