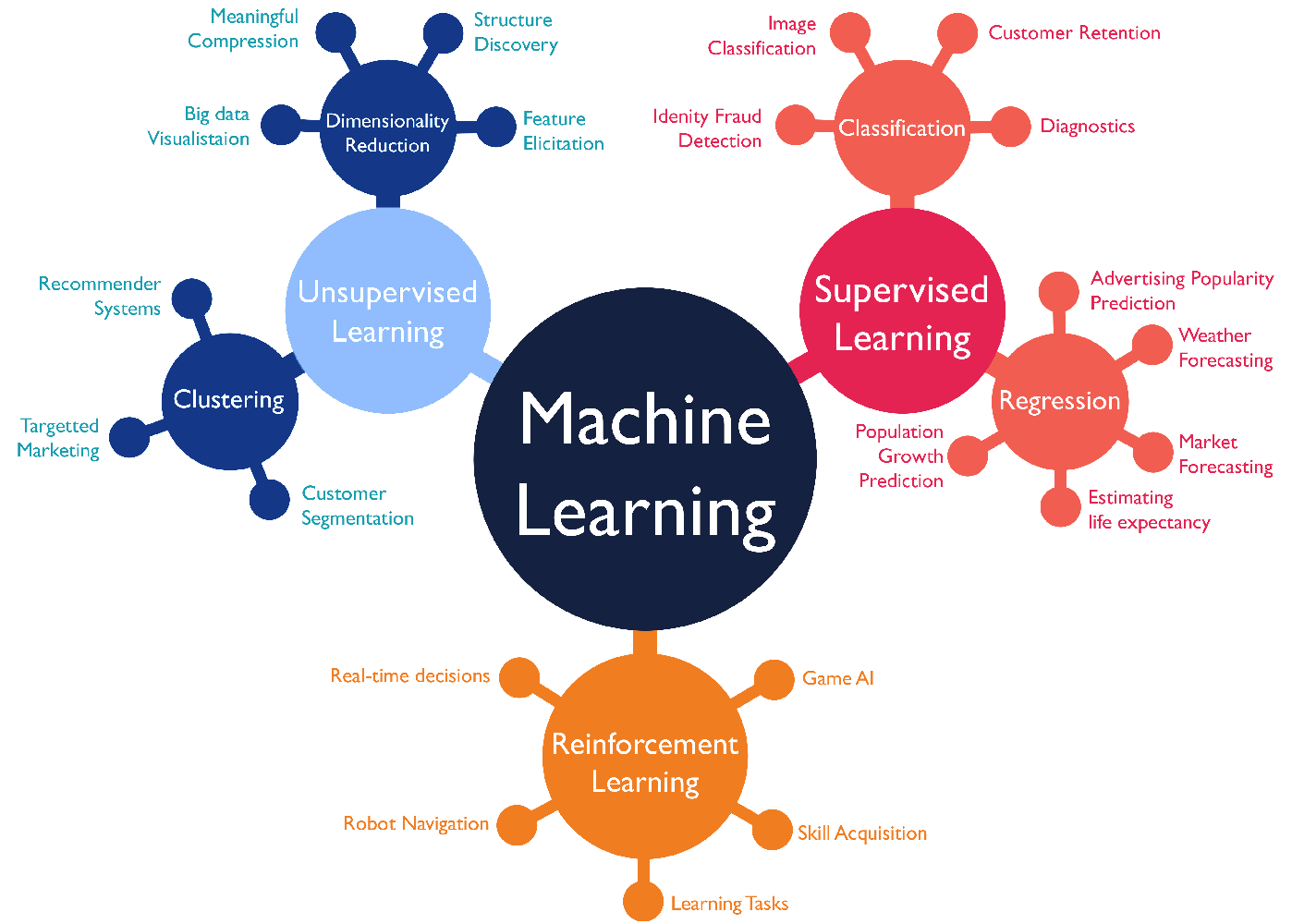
AdaBoost: AdaBoost: Fits a sequence of weak learners on repeatadly modified data. The modifications are based on errors made by previous learners scikit
Classification: 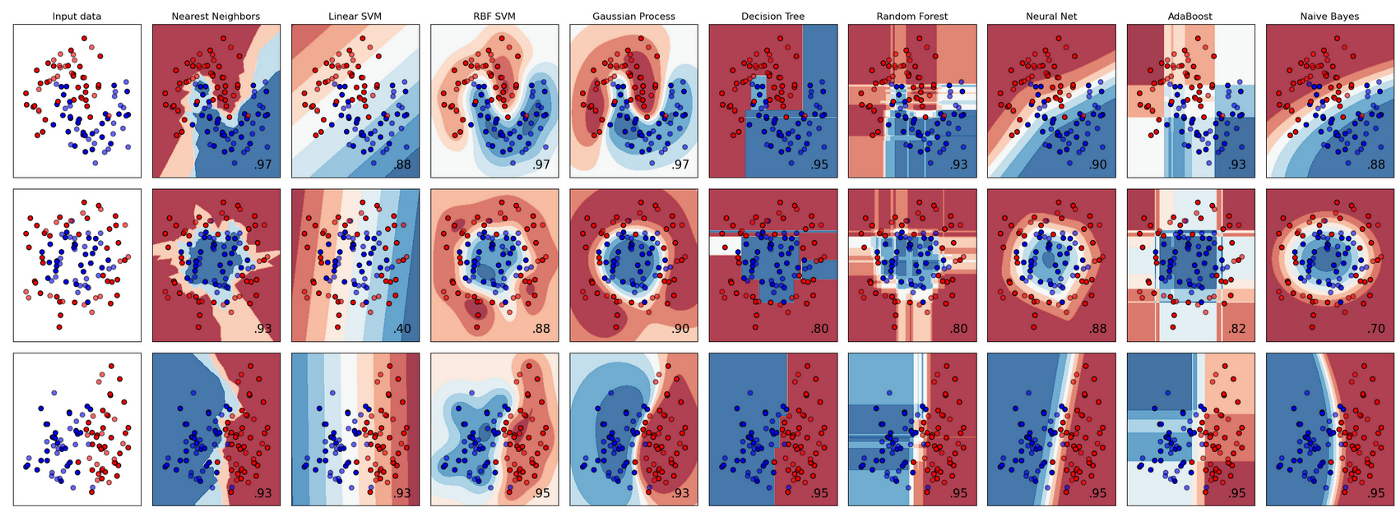 scikit
scikit
Distance metrics: Euclidean, Cosine, Hamming, Manhattan tutorial
Expectation-maximization (EM): Algo assumes random components and computes for each point a probability of being generated by each component of the model. Then iteratively tweaks the parameters to maximize the likelihood of the data given those assignments. Example: Gaussian Mixture
Gaussian Mixtures: anomaly detection example: future examples may look nothing like the past. This is where supervised learning differs because it assumes that future examples fall within the range of the training data
Gradient Boosting: optimization of arbitrary differentiable loss functions.
converting notebook to html using
jupyter nbconvert --to html --no-input --no-prompt '/content/drive/My Drive/Colab Notebooks/ml_notes.ipynb' --output ml_notes.html
[NbConvertApp] Converting notebook /content/drive/My Drive/Colab Notebooks/ml_notes.ipynb to html [NbConvertApp] Writing 578009 bytes to /content/drive/My Drive/Colab Notebooks/ml_notes.html